
As part of a two-post series, I'd like to share some in-depth details behind one of RunKit's most asked about features: time traveling. In this first installment I'll be focusing mainly on how the back-end works: specifically, how we're able to not only rewind the state of your code, but any changes to the filesystem and spawned subprocesses as well. From a high level, this allows for a lot of cool functionality like real undo in a REPL. However, we'll also see how time traveling is actually essential to the way notebooks fundamentally work in RunKit.
Why Time Traveling is Important
One of the earliest design goals for RunKit was that notebooks should just be node modules. There should be no real need for a "RunKit file format" per se: you should be able to download a notebook as a node module and get the same results by running it yourself in a vanilla node distribution. And it should follow that you should of course also be able to import one notebook from another, making them composable and truly shareable. Kind of like a cross between Wikipedia and GitHub, we wanted to transform code files into living documents where you could dig deeper into connected live, literate, code:
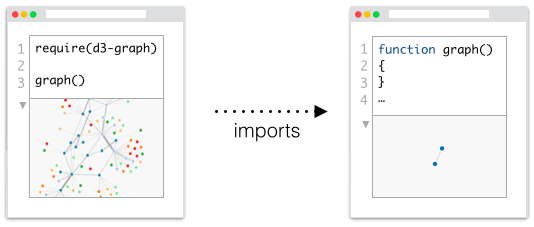
This is actually a pretty big departure from the way many existing notebook environments currently work. Systems like Jupyter (which we took great inspiration from) function more as UI layers that communicate with a background REPL, and so they unfortunatley also suffer from many of the same runtime limitations of traditional REPLs. Namely, code that's been run can't really be "un-run" or changed.
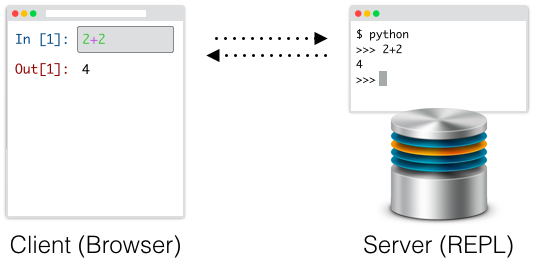
Environments like this are fundamentally append-only. Jupyter allows you to edit and re-run old code cells, but while it may visually appear that this new code has "replaced" the old code like in RunKit, in actuality it is simply being run on top of everything that's already been executed. This means that the document the user sees can quickly diverge from the actual document that was run. Lines of code will appear in a different order than they were run, and some lines may be missing altogether:

With such a model, features like requiring notebooks or downloading truly reproducible representations becomes difficult to accomplish and even to understand. How should a document be interpreted when it is imported by another notebook? Should it execute the cells in the order they appear, or the order they were originally run, and what is to be done of cells that no longer appear in the document at all but were a part of its execution history?
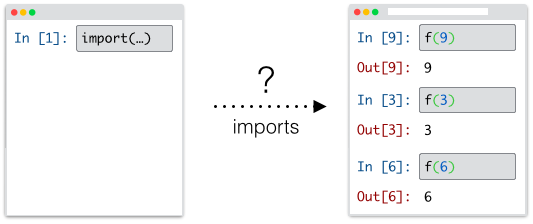
So while having time traveling integrated seemlessly certainly provides a more intuitive and direct experience when editing code in notebooks, it also quickly became apparent to us that it would also be absolutely necessary if we wanted to truly deliver on a living document that could be easily shared, composed, and re-run.
First Approaches
Explaining the ideal behavior of our notebooks is relatively simple: regardless of how you enter or edit cells, it should show the results of executing the file from top to bottom: the same way node does. The easiest way to accomplish this of course is to just re-run the entire document from the start after every change. This is in fact how the "rewind" feature in works in bpython. Of course, this quickly becomes unbearably slow with each additional cell you add, especially if the earlier cells are performing any networking or I/O. Additionally, if you had made use of any random variables, they would change right from under you with every change!
A different approach is to try to serialize the state of the runtime, such that you can unserialize it later to get things back to the same state. If you've ever worked in a pure functional programming language, you're probably familiar with this strategy and it can be pretty successful. On an application level, it is trivial to simply save your top level immutable data structures, and rewind by simply loading an older one. However, in JavaScript it is non-trivial to even access the entire state of your program. Any variables trapped in a closure are by design completely opaque to the outside world, and thus can't really be saved or restored. Additionaly, even in a pure functional context its difficult to store the state of things outside your application.
You can however imagine taking a step back and applying this same idea to your entire computer, instead of just your runtime. What if you simply took the current state of your memory and wrote it out to disk? Then, you could read it back at a later time and re-bootstrap the entire process. This is a very similar idea to what your computer does when it goes to sleep, or even kind of what it does when it pages memory out of inactive processes. In both cases it then reads that memory back in to "pick up where it left off".
It turns out you can execute some control over this by using a virtual machine. From a high level, a virtual machine hosts and entire OS inside of a process. This virtualized OS could then run a similar REPL setup to what Jupyter uses:
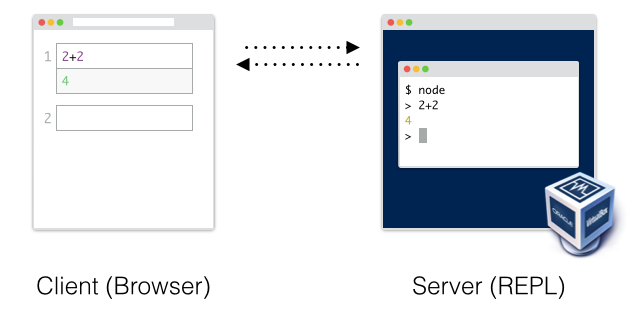
Now after running each cell, you can have the virtual machine create a "snapshot" of the computer. A snapshot simply stores the entire contents of memory of the computer, as well as the current state of the filesystem, and stores it in a file. At this point you essentially have "frozen" states of the entire computer for every cell the user has ever run. To rewind, simply restart the computer from and old checkpoint and run the new code from there as if the other cells never happened.
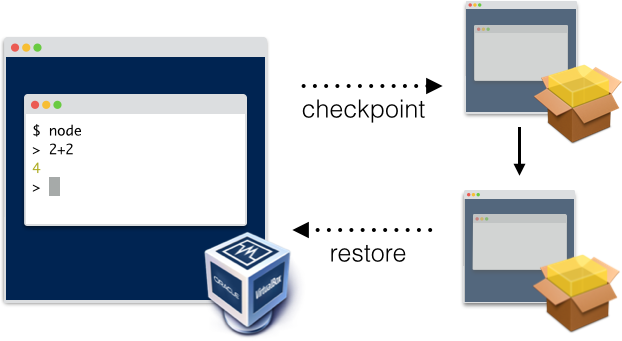
This setup is ideal from a behavior perspective, and even performs alright for a few notebooks. However, this doesn't scale. Virtual machines are pretty heavy, and running one for every notebook every user opens quickly becomes infeasible.
Checkpoint and Restore In User Space (CRIU)
Fortunately we were able to take a different approach thanks to an ambitious open source project called CRIU (which stands for checkpoint and restore in user space). The name says it all. CRIU aims to give you the same checkpointing capability for a process tree that virtual machines give you for an entire computer. This is no small task: CRIU incorporates a lot of lessons learned from earlier attempts at similar functionality, and years of discussion and work with the Linux kernel team. The most common use case of CRIU is to allow migrating containers from one computer to another. If you happened to be at DockerCon this year, you might have seen their demo where they actually did this with a running game server.
Who would have guessed that it could also be used to make JavaScript even more dynamic? The next step was to get CRIU working well with Docker. The CRIU developers have been incredibly supportive in this task, and Ross has been working closely with them to make this a first class feature of Docker. So with this final piece of the puzzle, we could now run our notebooks in Docker containers (which are considerably more light-weight than a full-blown virtual machine). Just like a virtual machine, after a given a code cell is run, we can immediately checkpoint the container (which stores the memory state of node, as well as any subprocesses it may have spawned), and commit the container (which stores the state of the filesystem). And just as before, if the user wishes to rewind, we simply resurrect the container using these two pieces of information.
Conclusion
Obviously there is a lot of infrastructure and operations work that goes alongside this to be able to properly support every user spinning up their own container of course, but this blog post gives a pretty good overview of the general concepts we use to pull off time traveling on the back-end in RunKit. Much of this work has been done in open source, and we'd love for more people to contribute to CRIU and to try other creative uses of the technology, it really is an amazing piece of software and we are incredibly thankful to that team.
In the next post I'll be covering the front-end aspects of making this all come together. There's a lot of tricky edge cases in JavaScript that require some interesting semantic work. If at any point you found yourself wondering how hoisting could work in a top-to-bottom environment that needs to behave the same as a module, then you won't want to miss it!
Also make sure to try some of this stuff out over at Runkit.
What is RunKit?
- RunKit is an interactive playground for running Node.js in the cloud.
- RunKit offers serverless functions with zero deploy time — prototype code changes in real time!
- RunKit can be embedded in your tutorials and docs to make them interactive as seen on lodash.com, expressjs.com, and stripe.com.
Follow @runkitdev on Twitter for the latest updates from RunKit
© 2015–2018 Playground Theory, Inc.